





�r�g��2013-02-26 ��Դ����h�Wwhw.cc ���ߣ�whw.cc ��Ҫ�m�e
�����˚gӭ��λ߀�^�������҂�����Apache�ĕ������@���҂��������кܶ�������Apache��^�Č��H���_�l�ߣ�������܉��б������ęC�������v�v�����ڌ��H�Ŀ����������������һЩ���}����������IJ��֣��҂�ÿһ�������c�r�g�����һЩ�܌��H�ļ��g���}��
�҂�������Hadoop�Ŀ�ˣ���CloudStack�ȵȈF꠵ijɆT�������һ�����^��Ȥ������һ���Fꠣ�Apache��һ���Fꠁ��v�vOpenOffice�M�뵽Apache��^֮��ͬ����r���Լ����Ї��İlչ��������ՈPeter Junge��
����L�x�xPeter������B��Apache�Ěvʷ�Լ�������հ��������IBM�Ї��_�l���ĵĽ������ҵĈF꠳ɆTҲ���cApache OpenOffice�_�l���^���С�
�������ú̵ܶĕr�g����Bһ�����@�Ӵ���_Դ��^���棬�҂�����������־Ը�߂������˳�����Щؕ�I���@�Ƿdz���Ȥ��Ԓ�}���_Դ�x�҂��dz���������҂���־Ը�߂�������߅��
���Ȇ�����ж��������^OpenOffice�@���aƷ�����d�^�����@ô���˶��e�֣��ж�����ȥ��^�D�^��������ʲô���}�܉�õ���𣬻�����ʲô�����܉����æ�������@���˾����˺ܶࡣ���䌍�����Ŀ�ľ������C�܉�����������ˁ텢�c�҂���^�_�l���ɞ��҂���^��һ�T��һ�����Ƅ��@���_Դ�Ŀ�˰lչ��
��ҿ��Կ������䌍�������ģ������҂���߅�������@��ܛ���@���棬�䌍�Ҵ�������һ�£��������ʮ�������Ա�������Ը�ߣ����@����^���湤����������������ʮ��Ҫ�������ã������Ё��������˾���߂��˵Ĺ��o�ߣ��ȷ�Peter����Ҳ�ڱ�������Ҳ���������Mȥ��
�@Щ���Ա�������Ը�ߣ���Apache OpenOffice�lչ�^���У������Ǯ���ȥ���һ��OracleÓ�x����Apache�@���^����ķdz����ĵ����ã������Ĺ������_�l�yԇ��������Ñ�������OӋ�������g�ȵȣ��ܶ�Ĺ����������ǮaƷ�ƏV�����˺ܴ�����á�
��OpenOffice����Apache��^�ԁ����҂��F��������4.0.1���@�Ǻܴ�Ʒ�|���Ñ��ݕ��ĕx������������Ը�߶����@��ʩչ���O����Ҫ�����á�
���c�˺�ֱ���а汾���_�l�����������������ú�Ҫ������Щ���ܵ���������Щ��ܛ�ęn�ļ����Ե��������҂��������˺ܶ��ؕ�I������߀��һЩ�Y�Y���}���ޏ͡�����ֵ�Ãɂ��f��ؕ�I��IBM�@߅�������_�l�������Ӣ��ؕ�I��������������˺ܶ��IBM�Լ��_�l�Ĺ��ܣ�����һЩ�ش�����ܕx����߀�����ښ�����ʿ���^�o��K�Ĺ��ܡ���һ����4.0�����҂�Ҫ���@Щ�|���Mһ���ĺ���Apache OpenOffice���棬�o�����Ñ����������档��һ�����И˵�����ؕ�I������UOF�ĸ�ʽ�����҂����ȵ��Ñ���һ���dz��õĸ������@���_�l�@߅��
�yԇ�@߅���҂����S����˽��뵽�yԇ���^���У���ȫ�Ǐ��^������@��һ���aƷ�Ĝyԇ�ܘ�����ҕԵ��䌍Apache��^���棬���T�ĮaƷ������Л]�������^����ᘌ�����һЩʲô�ӵ��Ñ����䌍��ֲ��aƷᘌ������_�l�T���ñ��f�҂���HTPServer���ȵ��@��һЩ���ߣ�����һ���_�l����OpenOffice��һ����������һ�����@����^������^��Ҋᘌ��K�O�Ñ��ĮaƷ�����Ĵ��a�����Լ��aƷ�����s�ȣ����������_Դ��^�aƷҪ���S�࣬�@�r���@�÷dz�����Ҫ���҂��yԇ���̎����˺ܴ�ľ���ֱ���^�����yԇ�����̣��\���ˮaƷ�_�a��������ȫ�^�̡�߀�_�l�����Ӝyԇ���_�����@������������^���潛�ɴ��̽ӑ��ʹ�õ�һЩ��ͬ��Ҳ���_Դ�Ĝyԇ�������ߣ��l������Һܿ�����������@���aƷ�����Ĝyԇ�v�ݰ����������@�ǜyԇ�����ؕ�I��
��һ���棬�҂�߀��һЩ�dz����F���YԴ���҂����Ñ��ݕ����҂��Ľ����OӋ�������Ĺ����ߣ��������H�ڞ�Apache��һ���汾���µĽ������ڱM������������Ҳ�кܶ�Ľ�B�������f�҂�����������Apache OpenOffice�������҂��к��Sʢ��ģ��죬�@��ģ�壬�������һ������ģ�K�Ļ����Ϲ��������������ęn�dz�Ӣ�������Ҳ����M̫��Ĺ����҂��OӋ��Ҳؕ�I�˺ܶ��ģ�����@������҂�ʹ�õ��@��ģ�����Դ���҂��������OӋ�ߣ��@���г�����һ��ģ�屻�W��Apache�����ʹ�ã������ܺõķ�����
����g�������@ôһ��ֱ���挦�K�O�Ñ��ĮaƷ�����g�L�̳�������Ҫ�ġ��҂�Apache OpenOffice�ѽ�����ȫ���g�����İ棬����һ�����_�l�и����҂��¹�Ч���_�lҪ�Mһ�������҂��ķ��g�����������҂��aƷ�ƏV���Wվ���g�䌍�@�����кܴ�IJ�࣬�����ҵ�OpenOffice�ľWվ�Ͽ�һ�����䌍���ľW퓟o���٣��@����Ҫ���ÿ����ȥؕ�I�ģ�һ���텢���@�����g�Ĺ�����
�Һܿ��^��һЩ��Ҫ���҂����Ա�����־Ը�����������@Щؕ�I���ҵ�Ŀ����ʲô�أ��dz����Σ���̖���ҁ������҂�����ʮ�������Ա�����־Ը�ߣ����д��ѽ��Ǵ���ֱ���ύ���a�ę������@�Ƿdz����������飬�ڇ��ȅ��cApache��^������f���@��һ���ܴ��������ҿ��Կ������҅Ⱥ���ҁ�������^�������҂�����̎���@Ȼ�������ڇ��⣬��������ܿ�����Щ��˾�����˵ĕr������ҕ�Dz������_�l��醚v���������Ժ�ϣ��ȥ������W�����ҹ�����Ԓ��������f����Apache OpenOffice��^�������^�_�l������һ���dz��dz��õģ����㺆�v�����һ�����c��
��Ը������܉��ʹ�����d���°汾��Apache OpenOffice�����ҽ���ٝ���҂�һ�����P�@���aƷ���䌍Apache OpenOffice������Ҫ�Ñ�Ⱥ�������ښW�ͱ��������ģ���ô�����Ҹе��҂��䌍߀�кܶ�����P���g�����棬����ұ��Ƚ��X�IOffice���]�д�ʩ�ĕr���䌍�ܶ��˲���֪���������ķ��������֪���҂��䌍�и���ľ�������档
��������֪�������кܶ༼�g�T�����g���ţ�Ը���ܼ����҂��������_�l���yԇ�@�ӵĹ�����߀��������һЩ���������������煢���҂��Wվ�ķ��g�ͱ��o�������o���҂�����һЩ�ˣ�����������^���棬�����ҵ�ʹ�ý�Ӗ�����o�҂���������OpenOffice���Ñ���ṩһЩ�����������f��������Ć��}�����ҵĽ�Ӗ�ҿ��Դ��ͣ��@���Ǐ��c�c�ε�����ģ����҂���^��ؕ�I�ܺõ����ӡ�
�䌍����һ���_Դ��^���䌍�Ҳ���һ�����c�r�g�dz��õģ����Ǐ�ȥ���_ʼ�ģ����X�����@���g���I����һ�N���H�����Q�ģ��_Դ��^���һ�N��գ��@���Ҹе����dz��И�Ȥ�����顣��Apache��^����������ͬ�ȵģ�ÿ�������骚���Ă��w��������Լ���ؕ�I��ÿ�fһ������ĕr���㲢���]�Й������Ȅe�������㣬������h�]�˷����ҾͿ����Լ��_ʼ����ȥ���ˣ���������ҵ����h�Ƿ��ˣ������˼����ң��@���_Դ��^��⿴����һ���Y����
���@���г������@Щ�_ʼ���c���������d�҂��ĮaƷ�����ļ����҂����]���б�������������һ���_�l���ґ�ԓ���ČW���ȏ�Apache�ʄt�����ґ�ԓ��ô��h������ô���]���}�ȵȣ��г������@��һЩ朽ӣ������@���҂����l��������Ҷ������������ȥ�ȸ衢�ٶ�һ��OpenOffice��ҾͿ����ҵ��҂���վ�c��ֱ��ȥ�����õ���Ϣ����ʲô���}������ֱ�����б������ҡ��@����һ�����εĽ�B����֪�������ʲô���}�����]��ʲô���}��Ԓ������Ո�������҂���BUOF���Լ��҂���˾��OpenOffice������һЩ������
������ң����ǁ������И�ܛ������˾�ģ�ؓ؟��˾Opensource�@�K�������҂���˾�IJ���ϵ�y��߀���ư�ȫ����ϵ�y��OfficeҲ��һ�K��������Ҫ���vOffice��
�ڽ���Apache������ϣ����҂��oOpenOffice����һЩؕ�I�������ڵ��e�k��Apache��������҂����Ĺ����ѽ��v��һ���֣�UOF�@�K߀�к��棬�����f����I���������k�����ӻ��@�K�Ǜ]���v�ģ������õ��@߅��һ�·���������Peter�ѽ���OpenOfficeǰ������߀�����Ďׂ������f�ú������ˡ��ҽ����vһ��UOF���Ї��đ��ã�UOF���εĽ�B��߀�о������ļ����Ԇ��}�Ľ�QӋ�����Լ�һЩ���ܡ�
�ں������@ô�ҹ�˾��ȥ����UOF�ęn��ʽ���������И�ܛ���������н�ɽ��߀��ܛ��߀��IBM��UOF�҂��Ї����ęn��ʽ�߶ȣ�����İl����һ��1.0�汾������2007��l���ġ���07�굽09��֮�g��ʼ�K�����ƣ���1.1��1.2��ʼ�K��1.3��09������һ���ݰ����@���ݰ��Y��֮���ڕ���һ���l�����F��߀�]�аl��2.0�汾��
UOF�@���ęn��2.0�汾��������ԭ��UOF�@���ęn��ʽ׃�������N��ʽ����������̎������UOT��ʽ����ӱ�����UOS��ʽ����ʾ�ĸ�����UOP�ĸ�ʽ���ɶ��^XMAL�ļ��M�ɵģ�2.0�^������ǰ1.0�İ汾���˽�UOF�ı��^�٣�������˽��Ԓ��2.0�汾����һЩ���M��ȥ����һЩLOGO��ID�������б��������˃Ȳ�ID�Ͷ�Ԫ�ķ�̖����Q��һЩ��һ�n�κ��^�m�n�ε�Ԫ���Pϵ�ȵȣ��@�������ڇ����ęn��ʽ�˜ʵ�һ���D��
UOF�ęn��ʽ�Ę˜ʣ���֧��ʲô��֧�և��ҵ��@��һ�������Ĺ��ģ����������Ķ�Ҫ����Ű桢�Y�����DZ��^�o�ģ�����Ҫ����һ�����w������̖�ĕr���@����ʽ�Ͳ�����ͨ�^����ҿ��Կ�һ���@��һ���؈D�����������k���ĕr�����f������@����̖���ܼ����������ȵȣ��@��ģ���ǽ��������ӆ��һ���µć��˵�ģ�壬�@��ģ����������Ҫ���������@���Ű��ʽ�������f�ҵ�һ����������һ��Ƕ����У�ÿһ���ж��ق����@�����Ї���Ҫ��ġ�
��ô���������������k���ęn��ֺ�һ��ͨ�õ��ęn���֮�g���D�Q�أ��@����Ͳ������ęn�߶��D�Q�Ć��}����XSLT����Q���ǿ�ʽ�Σ�����һ���ęn�D����XMAL�ęn���@������Import process����һ���ęn���а����Ĕ�������Ȼ�@�������փɂ����T���҂����Լ�ҕ�l�@�ӵĔ����D����һ��64���ģ�Ȼ�����׃�ɣ��ϲ���һ��FLATS�@��һ���ļ���֮���ٰ���ݔ����һ��ODF��
�r�g�P��Ҳ�f�ñ��^�죬���ܴ��ֻ��һ�������ϵ����R���F���҂��������Ĺ���Ҳ����Ҫ��QһЩ���@���^��֮�гʬF��һЩ���}��Ȼ���2.0��UOF���a�M�б��o���dz��g�ʹ���܉�����҂�ȥ���@�����顣�@��UOFؕ�I���@һ�K��
�����ҕ��vһ��ApacheOpenOffice����I���������k���Ԅӻ��I���еđ��ã��ஔ���҂�����ApacheOpenOffice����һ����Q������
�����ҕ��֎ׂ����棬һ���Ǽ��g�Ľ�Q������߀�Е���Ҫ�ļ������fһ�£�Firefox���h���ęn�IJ������������Ўׂ����ӣ������ģ�܊꠵ģ�߀���t���ИI�ģ������һ��С����
���g��Q����֮�У������ҕ��o���չ�Fһ��Firefox�ĈD��Ȼ���DZO �����C�ƣ�������ęn�ęC�ơ��@���D����Firefox���������̈D���tɫ�����Ŀ��������һ���g�[����plugins����һ�����������Office�Ć��ӣ��ڶ����Ǹ�Ӣ�Ę���ͨӍ���������Dz��ֱO �C�ƣ����һ�������h���ęn�IJ��������挦�ڲ������x��֮�g��ʲô�ӵķ�ʽ�M���D�Q���@��һ��Ӣ�Ę�Ľ�B���Ҳ����v��Ŀ�ľ����D�QFirefox�����JS��Firefox���֮�g����һ�Nϵ��
���ڱO �ͷ����C�ƣ�������x�����������ˡ��I�P�Ą�������Ȼ�@Щ����������ᘌ��cOffice�����������ģ�����Office�����M�в������������I�@Щ�������@Щ������ôOffice֪����������һ���O �ęC�ƣ����F���ⲿ�ӿ�ȥ��QOffice�Ȳ��Ė|������Ȼ���_��Ҳ�ǻ��ڄ����v��UNO�Č��`���@������Liscens�ܘ��D�����Կ�һ�¡�
֮������h���ęn�������҂��ṩ�ɷN��һ�N�nj����h�̵��ļ���ݵ��@��һ�N�������ҵ�JS���a���nj��ڷ����悀��Office�IJ�������һ����Dz��������@Щ�����c����M�М�ͨ��һЩ���a�ģ��@������Ŀ���DZ���ƽ���������ն˲�����Ԓ����ȫ������Ҫ���ϵġ�
��ǰ����JS���b�@���ӿڵĺ�̎�кܶ࣬�����҂��Ľӿ����@�ӵģ��҂���JS���b֮�����͕����@Щ�ӿ��D���ɣ�����Խo�κΈF�w�̻����_�l��ȥ�������ýo���_��Office�@�K�ӿڣ�ֻҪ�o��һ��JS�Ľӿڣ����Ϳ���������Ҫ�����κ����顣�@������һЩ��̎�������f���^�������_�l�ٶȿ죬���Ԍ��Լ���ϵ�y�����ƣ����^����ʹ�á��@���҂���һЩ�������҄����f��ֻ����Firefox�еIJ������Ȼ�҂��@������кܶ�N��������Windows�C����Ҳ��һЩ�ؼ����@�������k���đ��ã������Firefox�ؼ��đ��á��@�������t���ИI�đ��ã��Ҿ��f�@ô�࣬С�Yһ�£��кܶ�N�ؼ������\���ںܶ����ИI�������v�@ô�ࡣ
��������Һã������ĕr�g���o�ң����ǁ�����IBM�Ą������������@�����}ǡ�ø��҂������@���ƣ���һ���҂�Office�aƷ��ô����ƽ�_����ô���҂�һЩ��Ҫ��Social���罻ܛ��������һ�𣬿�һ���҂��ęn̎�������Ǻ��ε��ęn̎�����ڽ���ĭh�����҂��и�������x������ʽ��
�F�ڴ�Ҷ�֪����������߀��Social���DZ��^�����ĸ������҂���һ��ܛ��߀�а����҂��Ľ�Q�������������@Щ�c���㶼������˼�f������ܛ���ġ�
�҂���һ��������˽���ƣ��й����ƣ��҂�OpenOffice���ǿ��������Mȥ�ģ��������Ǫ��Ƶ����摪��ܛ�����҂�����˼��һ�£��ڬF����Ϣ��ը�ĕr�ڣ��҂���ô�����ƕr�ڣ���Social�r��̎���҂����ęn�أ����ȵ����滯�ǟo�ȳ����ģ������ƿ͑���ȥ���L�ĕr��Ҫ����Listens�ı��X���}��
�ڇ��Ⱥܶ��˶֪�������ęn̎���@һ�K���҂�������һ��ȡ�ᣬ�����҂���OpenOffice���҂��vһ�¬F�ڟo̎���ڣ�����Social���҂�ÿһ�������϶���һ��Ų����ֹ�������҂��o̎���ڵğo���W�j���������������vӍ��,��Ӌ�㌍ʩ��Facebook�@Щ�����҂�Social��һЩ��Ϣ�������������҂�������҂����ęn̎���ĕr��ȥ�����@Щ��Ϣ�أ���ô��ȥ���҂��Լ�����һЩ���£������o�����ˣ����҂���OpenOffice�ĕr���҂���һ�N�Uչ�C�ƣ������҂������ȥ���҂�����@ЩSocialServer��һЩ���ɣ��䌍�@�Nģʽ��ֹ������OpenOffice���䌍���Ҳ���Կ�һ�����҂���һЩ�Լ��đ��ã��䌍Ҳ��ȫ���Բ����@�ӵļܘ�ȥ��һЩ�Uչ�����҂��ķ����B���������F���кܶ˾�϶�Ҳ���@��ȥ���ġ�
�@�����ᵽ��Social Cnnectors�@�������ô�����ϵ������������ƫ���g�ĕ��h�����Կ��������҂����g�Ǒ�����һϵ�е�Social�@Щ�ӿڣ��҂����@Щ�ӿھͿ��ԏķ����������õ��҂���Ҫ�Ĕ�������ǰ�����҂��Ŀ͑��C�ϣ��������҂����������ϣ��҂�ͨ�^�@��һϵ�в�����܉���҂��Ĕ����������ęn���棬���^��Ҳ��һ�ӣ��҂������҂������ęn�����o��e�ˣ��@��������һ��ȫ�ęn�ķ�����Ҳ������һЩ��ϢƬ��ķ�����
�@�������ҿ��Կ����������v������Social�đ��ã��@������һ�N�����Ƶđ��ã������ƺܺ��Σ����܉����κεط�ȥ�L���@�����棬�@������F��������̓�M���g���ڇ���Ҳ��Խ��Խ���صģ������������ϵ�ܛ�����䌍����һ��LI�ɱ����]�Ć��}������Ƶķ����̣��ṩһ���]��LI��ܛ���䌍��һ���ܴ���������}�ģ��@����OpenOffice�ṩ��һ�Nȡ�ᣬ�܉��҂��Ñ���¸ҵ�ȥʹ��������ęn̎���Ĺ��ߣ�����ǰ���҂�Ҳ�v�����҂���OpenOffice������ǿ����õ�����ԭ���a���S��ȥ���°l�����������Լ��Ķ��x���Ă����֣������Q���⚤�������Լ�һЩ���еĹ��ܾͿ���ȥ���҂��̘Iܛ���ϵđ��á�
�@�����҂���������ȥ���҂���OpenOffice��
�҂����Կ�һ���҂�����ʾ���҂�OpenOffice����Ώ��҂��罻�h����ȥ��һЩ��Ϣ���ռ����@����ʾ��һ���ܺ��εĈ�����������һ�����壬��ϣ�����ҵ��罻�W�j�����ռ�һЩ��Ҋ������ǰ���@Щ���������Ұ��@���ļ��ęnͨ�^�]���l�ͽo�����ˣ���e��ͨ�^�]�����������F�����҂��@�Nģʽ�£��҂����Կ�һ�����҂�����ι����ġ�������@һ퓵���棬����ȥ�ռ���ҵķ������ҿ���ͨ�^�҂��҂ȹ��߲�������ٰ��@����棬ֱ�Ӱl�����ҵ��罻�Wվ��ȥ�����Ұl�����Ժ����ҵľWվ�����P���Pע�ҵ��ˣ��Ϳ��Կ����������Ϳ���ٿ�صĽo��һ���؏ͣ��@�������õ���IBM��һ���aƷ���䌍�@�N�C���҂���ȫ���ԑ��ðl��Facebook����������ȥ�����@�����ҵĹ��£��������ҵĽ��킃�������Ұl�����@����棬��ҽo��һЩ�Ŀ�������ֱ�Ӿ����@���W���ȥ��������������Ҋ���ã������Ժ����Dz���Ҫ�ٵ���ҵľWվ�Ё�����ֱ�Ӿ����ęn���g������ֱ�ӿ��Կ����e�˽o�ҵ���Ҋ���@���r���Ҹ����@����Ҋ�Ϳ�����������ġ�
��ҿ����@�N������ʽ���҂����Կ����������ĺî�ǰ���Գ��m�����������顣ͬ�ӵĈ������ڮ���Server�@�N�h���У�ͨ�^�҂��Uչ�ķ�ʽ�ܿ�͵��_�ˣ�����қ]���@�ӵ�Social�ļ��ɣ��҂����l�F�҂�Ҫ��һ�κ��L��·�����ҵȺ�ĕr�gҲ�Ǜ]����ô��Ч����
�����f��ҿ������҂�OpenOffice�����H���ęn���g����Ҳ��һ���U����ƽ�_����ô�@��ƽ�_���ܽo�҂��ṩ���N�ĔUչ���ܣ��@������ʾ���Ǹ�Social����һ�����ɡ��䌍�҂�����������ĸ��ęn�惦�������҂��ٶȵ��Ď죬߀�и��������ϔ����Ĵ惦���������@�Nȥ�Pϵ������
�҂��������҂����_�l���ߣ��@���_�l��Ҳ����һ���_Դ�Ĺ��ߣ���Ҷ���������^�Wվ�Ы@ȡ�����҂��\����һ���_�l�ӿڣ��@���ӿ�Ҳ�Ǵ�ҿ����S��@ȡ���ģ�UNO�Ľӿڣ���^�@߅�кܺõ��_�l�փԣ��҂��_�l�ˆT��Ը�������һش�һЩ���}��
���w���f�@�������҂������v���ģ�������҂�����^���棬��OpenOffice��һЩ�Ƹ�Social�ϵ�һЩ���ɣ��@��������һ��̖���ҁ������҂�OpenOffice�@�����ͥ�������������ȥؕ�I�Լ������⣬Ҳ���Ի���OpenOffice�@��ƽ�_ȥ�������Լ��đ��ú��Լ��Ľ�Q����������������õ�OpenOffice�Ĵ��a��Ȼ�������Լ����ġ����������dȤ��Ԓ�����е����鶼����ͨ�^�҂����]���б��@ȡ���������҂��ļ��g�ˆT�@�K�����҂��ľWվ�_ʼ��һ�����^�õĵط����x�x��ң�
������ʮ�ָм�Apache��OpenOffice��OpenOffice����ǰ��SUN����������^֮����֏�Oracle�D�����Ƶ�Apache��^��Ҳ��醚v���L�ڶ��D�y���M�̣�һ���aƷ���Ҫ���и������������������@�NNGO��ģʽ�������������ܕ������L�ڣ��@���L�ڴ�ҷ�I��^��һ�����R�ĮaƷ�����ֻ���Q���ЄӵIJ����������U����Ԓ�����H���Ǻ���ϧ���¼����҂�ՈRaymieՄһՄHadoop�µ�Resource Manager�ĮaƷ��
RaymieӢ��
�����˷dz����xRaymie�������o�҂�������ɫ�Ĉ�档������Ո����VMware�ž�ƽ���v�vHadoop��Virtuallzation��
�҂����������}Ҳ����Ӌ��������Ҳ�nj��ڽ�����r�d��һ���~���ϵ����ȿ������µ���������Ҷ�����ٌ���Ӌ�㶼��һЩ���ã��@������һЩ��ĭ�ijɷ������档�����҂��Ԟ���Ӌ���܉���I��IT�\�S���X���ڶ�������p���˺ܶ���I��Ӳ��������ͨ�^̓�M�����Ԝp�ٺܶ�Ӳ����֧����������֧����������Դ��֧���������Էdz�Ѹ�ٞ���I�ṩIT���գ������҂��F��������һ�����^�õ���Ӌ��ĕr����
��ô���ڴ������f��I�Ĕ����������ԣ���I�в�ͬ��������������Щ�ǂ��y�Ĕ���������߀����ҪHadoop�@�ӵĴ�ƽ�_���҂����е�IT����������һ��һ���u����I�в�ͬ�����ڽ��I��ͬ��ϵ�y�������������������һ���yһ�ģ������в�ͬ����Hadoop�ĵȵȣ������������ܺõĹ�����
�������ԣ��ۂ�����ͨ�^̓���������õ���ȫ����ƽ�_���҂�Ŀ���ж����c�������҂���ͬһ����ƽ�_������õģ����������Ҫ�������o����̎�õ�ƽ�_���P����ܵļ�Ⱥ�������҂��d�S���ڽyһ����ƽ�_֮�ϣ��Ѳ�ͬ���\���M�л��s��������Щ�\����CPU�ģ���һЩ�����ǃȴ�ģ���ͬ�đ��Ì��YԴ�в�ͬ����Ҫ���҂����������ͬһ��ƽ�_�ϰ��@Щ���úܺõĻ��s��������ô�ۂ��܉��M��ȫ���YԴ�đ����ʡ�
���挦�ڴ�ƽ�_���ԣ��ŵ�һ����ƽ�_������һ��̓�M��ƽ�_�ϣ��������ʬF�κε�ˮ�������أ���������������кܶ���`�ɵ��@�N����ķ�ʽ���@�N����ʽ��������Ĕ���������ԣ����ܶ���Ҫ�{�����҂���ҪһЩ�~��ȥ̎���@Щ���顣
���w����������Ӌ�㣬����̓�M�����҂�����Hadoop�܉��������Ե���s���܉��������^�����_���߿����ԡ��и��õĹ������x��������Ӌ��Ҳ�ã���I�IJ�ͬ�������ģ����ߔ��������Ƿdz���Ҫ�ġ�
�����҂�Ҫ����õ�̓�M����ƽ�_���҂���������Щ�£�����ȥ���҂��l��һ����Ƥ������Hadoop��̓�M��ƽ�_�����ܵ����������ܴ��Ҳ�����^�P���@�����}�������ҕ����ν�Bһ�¡������҂��x�S���ӵ�Apache��Hadoop��^���棬���@����^��һЩؕ�I,˽������Hadoop��̓�M������Ӌ���ƽ�_��ȥ���I�ø��á�Ҳ�����ҽ�����ҪҪ��B�ă��ݡ��҂�߀��һЩ�Ŀ���҂�����������_�l����Ҫ���@�����ֵă��ݡ�
�@��һ���������҂���Virtuallzation5���潛�ɺܺõ��{ԇ֮���҂��l���������đ���һ�ӣ����A����̓�M��������Ӌ��ƽ�_���\��Hadoop�����@�ӵ�ƽ�_�����������ęC�ܺ��Ҳ���U�õģ�������5%��10%�����܆�ʧ�ʡ��҂���̎�����^���У��҂����˺Îׂ�Ӌ���������҂����S����ʮ�ׂ�Server���棬��̓�M��֮ǰ��̓����֮�����˱��^��ÿ���Y�c�Ўׂ��ƾ`���҂����˸��N���ӵČ��ա�
�����Bһ���҂���Hadoop Virtuallzation��Hadoop��̓�M����ƽ�_��������һЩ�Uչ�̓������҂��@���Ŀ��Ҫ����һЩ�����Ĺ������҂��@���Ŀ���Įa���ύ��Hadoop�����Ñ������գ�Ȼ���_�����õă�����Ч����ͬ�r������^���������һЩ���,̓�M����ȫ���@��HVE��Ҫ�ǎ�헹������҂�Ҫ֧��code base���ڶ����Ƶĭh���£��@Щ�YԴ������ϵ�y������YԴ�������㌍�H����ȡ�õ��YԴ���@Ҳ���҂���Ҫ���]�ġ��҂��F�������������ǣ��҂���ͬ�ӵ������b���ϣ��҂���̓�M�Y�c��Ӌ��Y�c�͔����Y�c�x�_���ҽ�����Ҫ��ӑՓ���ӵľW�j�Y�����Լ�������Ӌ��Y�c�քe��
�����f��Hadoop��Hadoop�����ӣ�һ����data center��һ����rack��һ����host������Ӌ������f��̓�M����ƽ�_�����и���IJ�ͬ�IJ���ʽ������㿼�]�ܶ����ù����ĕr������ܕ����@�ӵęC��̓�M��֮��ֳɶ����C���������f�����I������Ҫ����Hadoop�ĽY�c�������@�����Y�c�㲻֪��ʲô�r���@Щ�Y�c�����壬ʲô�r�ȣ��������������ͬ��һ�����^��ļ�Ⱥ���棬�����@Щ��Ⱥ�����S���㑪�õ���Ҫ�����ԔUչ���߉��s����������ͬ����IJ���ʽ�_��Ҳ��һ�ӡ�
��һ�N��������A�ģ�����һ��VM���@�Ǹ������h���]ʲô��e���ڶ������ܕ��ж����Y�c���F�����^���Ă��������������һЩ�yԇ�������Ĺ��������ܳ���ʮ������ʮ������������ĽY�c���������������f�������ķքe�����Ă������߀���ж���data note����M�������Ҫ���@�N��r�£������Hadoop�Ͳ��ܝM����������ˣ��F���҂��������@��node group�@һ�ӡ��F���҂������Д������P�IJ����҂�������һ��̎�����������@Щ�҂��ģ�Hadoop߀���������h���Р�B�ܺã��ŵ���ƽ�_����̓�M��ƽ�_֮�оͿ�����һ����ͬ��Ӣ�ġ�
��һ�����εĽ�B���O���@���ڸ����ķ��ò����ϣ�2��3���ڽyһ��VM�ϣ��F�ھͲ����уɂ�����ͬһ��node�ϡ��@���nj��ڸ������x�IJ��Ե���չ������ȥ�x�yһ��Ӣ�ġ�
���ھ��������ԣ�ϣ�������ķ������f���ο��ģ���ȻҪ֪��֮ǰ���@ЩҎ�أ�߀Ҫ���C�@Щ��������ȫ�_���ο���Ҫ��ģ������҂�Ҳ�OӋ�˺ܶ��@�����߉��
�����@���x�յķ���Ҳ��ͬ�ӵ��������҂���������nj��ڔ�����Ӌ����x�Y�c����r�£��@һ���@�ø�����Ҫ����������֮ǰ���Ñ���f�������l�F�@���Y�c�]�б�����node�����ĕr�������J���@�������Dz����J�R�ģ��҂��Ĺ����@��Ӌ������N��������Hadoop���YԴ���Џ��ԣ�������Hadoop���������ܕ��ڽ�����m�m���ӵ���^���档
����Ո�ҵĹ��½o��ҽ�Bһ��Serengeti���@��һ�������ģ��_Դ��һ���Ŀ��
���e�҂���Serengeti��һ����ȫOpensource�ģ��҂��@���Ŀÿ�������l��һ��С�ĽY�����@����Կ����Ўׂ����c,�����惦���ܷ���ȥ���𣬺ܷ���ȥ����Hadoop Project��
�҂����ε�����C���棬ֱ�Ӱᵽ̓�M�C��ȥ�\�оͺ��ˣ��]��ʲô����ĵط���������̓�M����ƽ�_����һ����ɫ������VM�@Щ�|���dz��ęC�ӡ��@���҂����һ����Hadoop���\��ģʽ�ϣ����ܕ������@ôһ�Nģʽ��
Ӣ�ġ�
�@�����҂��ᵽ�Uչ�ԣ�����һ���ܺ��ε�…���ض���…���҂���һ��…�����茑���҂���…�Lʲô���ӣ��҂����p��ȥ…����һ���҂��Q��…�������҂�…���傀���҂���…���傀���ҿ����f�҂�׃��ʮ���������傀VMware����…��Ȼ��…��…���档
�����҂�Ҫ�\��Hadoop�҂���Ȼ���뵽���҂���ô���C�P�I�đ��ò�������Ⱥ��Ӱ푡���ijһ���ض��ĕr���ԄӑB��ȥӢ�ģ����������İY�Y�đ��ò�����Hadoopռ�á�
�@���䌍����ľ��ǵ���Ӣ�ģ���Ҫ��������������]�������҂�ȥ����Hadoop�ĕr���҂�Ҫȥ…׃�÷dz����Σ������_ʼ��ôȥ����һ���µļ�Ⱥ�����\���^��������ô…���҂�Hadoop�\����…�ϵĕr���@߅���Կ����_���кܶ����H�����������档�҂�֪��������Hadoop��Ⱥ���棬���c���ϣ��҂�������Vsphere��һ���І��}��������������һ����ǡ���҂����@������Ҫ�����܉���_�l�҂��ĮaƷ���҂������ܵđ���Vsphere�Ĺ��ܣ��҂��������и����ܵ��ϣ����������������ô��ȥ���á�
�@���҂�HVE�Ĺ���������Project Serengeti���������Vsphere�ĭh��������ֱ�Ӳ��𣬄���Hadoop�ļ�Ⱥ���gӭ���ʹ�á���������ᘌ���ᘌ�HVE������ᘌ�Vsphere��
�ᆖ…
���e�@��һ���ܺõĆ��}���҂�֪�����Ќ�̓�M���h��������Ҫ�����ɲ��ֹ�����һ���ǰ�node�A��ã���һ�����ǰ�Source���������ڰ������ѽ��������҂��������c���҂���Vsphere�@��ƽ�_��ȥ����Ⱥ��
�ᆖ…
���e�ļ���64�מ��λ�����ж��ق�������
�ᆖ�䌍�Ҍ��_Դ�DŽ����|���Ǻ�������Ȼ���Ҳ�֪������B�ĕr����]���ᵽ���U���@�ֲ���������ô���ģ�
���eHadoop������һ�ױ��U����ϵ�y���@���ļ�ϵ�y�в�ͬ���Ñ���߀����һЩ�����Ć��}������Ӣ�ģ����^���s�������ǔ�������Ȳ������ܲ���ȥ�_�������J�C�Ĺ�����
�ᆖ��Ȼ����һ���_�ŵĖ|�����Dz��DZ�ʾ����������д����ܛ�����_�l�߾Ϳ��Է�һЩ���}�Ė|�������^��
���e���ύ���a�ĕr����Ї����Č�����������nj�Hadoop���f�����Ĕ�Ŀ�Ǻ����ģ��҂����l�F�҂��Ї��F�ڹ��������˕r�^��߀�]��һ��������Ҫ��֪������^��ܶ���ˣ��@���DŽ��������Ƶģ��ǽo�ˎ�����̎�ģ����������⌑���a�Ϳ����ύ�ġ�
�ᆖ…
���eVsphere�������@��������…���҂�����ȥ…�Ĺ��ܣ��҂���֪���@��VMware�Dz��������w�ƣ�ʣ�µ��@Щ�YԴ߀��Vsphere�����õġ��x�x��ң�
�O�����ҽ��쎧���Ę��}��CloudStack�������Ҏ������ǰ���������һ��Opensource IaaS��CloudStack������څ�ݿƼ���ͬ�rҲ�ǰ�����ģ�����Ҳ���MCloudStack���Ї��İlչ��
��������Ҫ�v�ɲ��֣���һ������Ұ�CloudStack�����w�fһ�£������ҕ���Bһ�¬F��CloudStack���Ї���^�İlչ��
���_ʼ֮ǰ�����vʲô��CloudStack֮ǰ���������J���б�Ҫ��CloudStack��������r�o��ҽ���һ�¡�
CloudStack�@���|������2008����VMOPS�@�ҹ�˾�_�l�ģ��������_�lCloudStack��Ȼ����2010��5�·ݣ�VMOPS��������CloudStackc769686b2e81f1c70bec1eddef8c��2.0�汾Ҳ�l���ˣ��o����ȥ��7�·ݣ��@�r��a��һ�����飬����˼�ܰ�CloudStack��ُ�ˣ��_�l��3.0�汾��˼��һֱ�_�l�Լ���CloudStack�汾������4�·ݣ�˼�ܰ�CloudStack�_Դļ��o��������^��10�·ݵĕr����һ��ֵ��ӛ�������飬CloudStack����^�����ݰl�����Լ��ĵ�һ���汾������CloudStack4.0��Ȼ���ڲ�δ�װ낀��ǰ����˹�S��˹��һ��CloudStack���������߅�e�У��@����������r��
ʲô��CloudStack������҂������@����������������������}Ҳ���_Դ�ƣ�CloudStack��ʲô�������f������һ����ƽ�_���@߅��һЩ����CloudStack�����c����֧�ֶ��������ƽ������s�ԣ���Ȼ��Ҳ���_Դ�ģ��F���ǰ�������S��CloudStack�ǵͳɱ��YԴ�O�ص���ƽ�_���@���^��ɂ���һ�����YԴ������һ�����ƣ������Ɓ��f���҂���֪���F���й����ƣ�˽���ƣ�����ƣ�߀������������^�������Ė|�����YԴ�o�Ǿ���һЩ�����YԴ������һЩ̓�M�YԴ�����Ӳ���CPU���ȴ��Լ��W�j�@Щ�YԴ��
��ҿ��Կ���߅���@���D��CloudStack�ǰ���������YԴ�M������̓�M��������ȥ�ܿأ����Լ������ṩ��һ���C�Ϲ��������档������������ȫ��API��ϵ�y����������nj����ṩһЩUI���������Լ���������YԴ��
�҂���һ���@���N�ƣ��҂�ƽ�r���ڹ����ơ�˽���ơ�����ƣ��@���N���Լ������Լ����@�����c���҂��ȿ�һ�¹����ƣ���Ҷ�֪���ģ����ǁ��R�d���ǵ䷶�Ĺ����ƣ��Ǻ܄����ģ��҂�����Ҳ��һЩ������Ŀǰ���f�����ģ����鹫������һЩ���c��Ҫ�M�⣬��Ҫ֧�ֶ������Ҫ���Է��գ�Ҫƽ�еĔUչ��������һ�N���踶�M�����ö����Ͷ����X���^�����f�ɱ���Ҫ�ѳֵ��ܵ͡�
�҂��ٿ�����߅���@����˽���ƣ�˽���Ƹ��������к����@�IJ�������f˽������ͨ������I������IT�Լ������õģ������YԴҲ���Լ����ٵġ����eһ����˾����Լ���ITҪ��˽���Ƶ�Ԓ����Ȼ�������Լ����ٵ��YԴ�����Լ����ٵ�IT���֣���ȫ���x�ľW�j����ȫ���@Щ������Ҫ���]�ġ�
����ƌ��H�Ͻ����@�ɷN��֮�g�����������Ҫ�ľ�����һЩ��I�����Լ���IT�йܳ������й�Ҳ��һ����Ҫ������Ҫ�ľ��ǿ�����Ҫ���ٵĞ���I�I��ķ�������Ҫ����һ����SOA�������_�ׂ�9���@���������^��ҕ���@���N������Լ�Ҫ��һ���Ƶ�Ԓ���ķN�Ʊ��^�m�ϣ�����ԅ����@����ɫ�����Լ��е�Ҫ����Щ���档�@�ǽo���һ�����ա�
����CloudStack�һ��S���v�@Щ���ݣ������@�DZȔMhigh level�ĈD���ж��ق��������Ը���ҽ���һ�£��@���D�����挑��һ��Zone����������ɞ锵�����룬��Ȼ�@��������ȫ��ͬ�ģ��������һ��pods���Զ��óəC���@������������Ǽ�Ⱥ��CloudStack����Ⱥ�бض���Ո����Ո��Ⱥ�Ȳ�������һ�µ�����C�������ڼ�Ⱥ����һЩ�w�㣬��Ⱥ�@һ��������߉��������ȔM��Ҫ��һ����Ȼ��Ⱥ�������Ԕ�������C�����Կ�����Ⱥ�@һ����߀�о���������惦��Ҳ���Լ�Ⱥ��߅��ģ�ÿһ����Ⱥ���H������Ҫ�����������惦������ѽ������惦��Ԓ��Secvondary���������YԴ���ǹ����ġ�
�@�N�YԴ���Ǻ���������ȥ�M�ϣ������������hypervison��VMWAREҲ������Server������Opensource��Ҳ������SUN��Ҳ������nfs����߅�Ƕ����惦��Ŀǰ���f֧�փɂ���һ���ǂ��y��nfs��CloudStack����Q�����ˣ����ڇ��⣬�ܶ�ҹ�˾���������кܶ�dz��õ�һЩ���ܡ�
�҂��ف���һ��CloudStack������OӋ��CloudStack���_ʼ�����Ǒ{�ճ����ˣ������OӋ��Դ�������҂��@߅��һ�����εı��^����߅��һ���������ĵļܘ�������������T����ͨ�^���Ӻ��ģ��B�����WELL���������ǙC�ܵ���˼��POD���M��U�_չ�����@�ǵ䷶�Ĕ������ġ��҂���һ���\�I�T�������@߅OSS���H�������ͬ�ġ��F�ڲ�ͬ�ĵط��ڙC���@һ��������һ��߉���֣��ڙC�����棬һ���C�ܿ�����������Ⱥ����Ⱥ�������������C���@�ӄ��ֳ����Ժ�һ��zone�Ϳ���ᘌ��������ģ������Ǻܴ��ĔUչ��߀��һ�c��һ�ӣ���߅��Secondary storyge����Ҫ��P���^��CloudStack������аlҲ���J�R���@һ�c���������惦�������OӋ�����惦�������惦��
�@�����Ǹ��N�����ģ����Ǟ��@�������OӋ�ģ������ڵ^���кܴ�Ŀ�ȣ�һ���ƭh����������Щ��˾�Îׂ��ط������k�µ��c���������ƭh���²��𡣱������ڱ������ҵĔ������ģ��ҕ���һ���YԴ������@���ҵ�Server�����@������������Ѓɂ�ZONE������һ�����@�Ǻ��Եĵ^�Uչ��CloudStack����ȫ֧�ֵġ�
�@߅��һЩ���εĔ���������CloudStackĿǰ�Uչ�Ե�����ʲô��r���҄����ᵽmanagement Server��һ�������������Y�c��Ŀǰ����֧�ֵ�һ�f�����ҵ��YԴ����Ȼ�@���YԴ����������������C��Ҳ�������������惦�������惦���Լ���Ľ����C���@Щ��������YԴ��������һ�������������Y�c����֧�ֵ�һ�f�������ڴ�Ҳ����Լ�˽����������õģ�������Щ�����Ʋ�δ�כ]�_���@��Ҏģ��
�����Ժ��Ե���չ�����ڹ����������Y�cǰ�棬����L�����ܴ�����ԼӶ��_������������ǰ���ؓ�dƽ��Ϳ�����ȫ���������������Pעһ�µ�Ԓ���ڰ�����CloudStack�@߅��һ���yԇ��������Ă�������������ؓ�dƽ�⣬����֧�����f���������YԴ�����f��̓�C��Ҏģ����Ȼ����@��һ�Nģ�¡�Ŀǰ�@�K߀�кܴ�ĸ��M���g������Ҫ������scalesout��������Ҫ��QһЩ����POST�ęC�ƣ�ͨ�^Scalesout��Ӌ��һ����������������֧�ֵ����f��resources��
���Ƶĕr�������O�κΖ|�������ɿ���CloudStack���@�N�ɿ��Է��浽������Щ�Լ������c�أ����Ⱦ���CloudStack���кܶ����ӻ����DZ��ӵķ�ʽ���Ԅӵķ�ʽ���ǣ����������ӑB���w�㣬�����Ұ����C�M���˞�S�o���ڿ��A֪�ĕr�����ҵ�Ӳ�P�Ɖ��ˣ��ҵăȴ���Ҫ���LһЩ�����@�N��r���H�������ӵ��Єӣ���ϵ�yijһ��resources�M�оS�o��߀��һ���DZ��ӣ��@�N��r�¶��Dz����A֪�ģ�����������@�N��r�����@�N��r���҂���Ҫ����Щ���飬����CloudStack�ṩ�˽�HA�ęC�ƣ��߿ɿ��ԵęC�ƣ���ֻ�а�̓�C����֮ǰ�����@�����հ�HA�o���ϣ��@�����C�ĵ��ˣ������@��̓�CServer�І��}�������ԄӰ�����������
CloudStack4.0������ǰ����һ���µĹ�Ч����һ�����C���Tᘌ�HA�����������ǿյģ�������Щ̓�C��HA��Ԓ����HA��̓�C�����Ƶ��@�����棬���ԄӸ����ӷ��涼���o�ˌ�HA�����֧�Ρ�
�҂�������һ�£�������ȫ�ԣ��ҕ������еļ��g������һ�¡�KVM���Ї����^�𣬹�Ȼ�ٷ��]���fҪ֧��12.0�������H��Ҳ��֧�ֵġ�
��ҿ��Կ�һ�������Լ��ֱ��̓�C��ʽ����̫һ�ӣ����Ƿ�֧�ֳ����@�N������Կ�һ�£���惦�ij��䣬�@�������f���е�Hypervison�������еĴ惦��֧�ֵġ�
Storage��һ�������惦��һ���Ƕ����惦�����惦��������LPSҪ�ܸߣ������惦���DŽ����v�ģ�����һ�Nһ�Ό��Ҵ��x�Ĵ惦�������@�N���f���H������LPS����Ҫ��ô�ߣ��������Ĵ惦�������^��ģ�塢SO�����ж���Ҫռ�ô����Ĵ惦�����R���@�����c������CloudStack�Ѵ惦�ֳ����@�ɷN��ͬ����r���в�ͬ����̎��
���溆�ν�Bһ��Network���Ұ�CloudStack֧�ֵăɷN�YԴ����һ�£���һ�N���ǻ����W�j�������W�j�����Ԟ���CloudStack�ĸ����YԴ����һ�����A�YԴ��ĕr���õ��@�N�W�j���ɷN��ͬɫ����ָ�ɂ���ͬ�Ñ����߃ɂ���ͬ����������Ñ�̓�C�������Լ��{���Լ���IP��ͨ�^�W�j������ӽ����M�л���ͨ�������O��һЩҎ�ء�ǰ���һ����������ͨ�^ƽ���M�ķ�ʽ�M�и��x�ģ��@�N�DZ��^���εġ�
߀��һ�N�Ǹߵ��YԴ����@�ͱ��^���s�ˣ��@���̓�M·������ÿ�����������Լ��Ϊ�̓�M·��������ؓ؟�ܶ�ľW�j���ܣ����ĸ��x�Ƕ��ӵĸ��x��Ҳ���ǻ���VLAN�M�и��x���ɂ���ͬ�Ŀ͑�������̓�M�C������IP���ǿ��Է��͵ģ��@�����ĸߵȾW�j���@�������ģ��@�����кܶ�N��ͬ�Ľ�ɫ����ͬ�ę��ޣ���K�Ñ����ܙ���Сһ�c������Ҳ֧��EC2��API����4.0���棬3.0Ҳ֧�֣���4.0������Mһ���ˡ��҂������������������õ���My SQL������Լ����@��My SQL�ļ�Ⱥ������Oracle��Ԓ����…���]���_Դ֮ǰ���@Щ�͑��������_Դ�ģ��F���@���ֿ͑������_Դ�ģ�����ϣ������ďS���M�������Լ�֧�ֵ��O�������M�����������һЩ����ϵ�y̓�M�C��
����ҬF����Ҫ���Ї����MCloudStack�Ї���^�������滨�c�r�g�o��ҽ�Bһ�°�����CloudStack�@����^���Լ��F�����Ї��Ġ�B������ҷ���һ�¡�
���Ȱ�����CloudStack���F������һ�����������Ŀ��������һ����ʽ���Ŀ��һ���ɞ���ʽ�Ŀ��һ���ܳɞ�TOP1�������^���ķN��ɫ������ô���ӵ��@��������CloudStack��^���������ķN���ݼ��M�������������Ñ���������һ��Ӣ�ģ�����…�M���������Ñ���Ԓ�����Ǒ��ÿ�����һЩ���ó��h�������nj���^��ؕ�I���������һ���_�l�߲��ǪM�x�Č����a����������ٝ�����͆��}���o����һЩ�ęn�������@Щ�¼���������I��
��Ҫ����ɞ�committer���ȱ��ȥ��ؕ�I����ҿ��������@�������Լ���ؕ�I���С�����һ���ǽ�mentor���@����ɫ�����������������Ƿdz��˽�ģ����Ԏ����@���Ŀ���棬�M��İ��հ���������́������顣��������֪���@���Ŀ����һЩ�T·����һ�����ǰ�����ľWվ����һЩ�|�������棬��ҿ��Կ���
�@�����ǰ������Mailing Lists���@�����돊�{�����@���]���M����CloudStack�@߅���Ї�߀���U���صģ��Ќ��T���]���M���@���ҿ���ӆ�һ�£��F��������ӑՓҲ�L�̳����[�ġ��ܶ�����CloudStack�ᆖ�}����������Ŀ��ܺܿ챻��Q���]���M�ǂ��Ö|����
���濴һ��CloudStack���Ї���^�İlչ�^�̣��@߅����ľ����҂�����ľ��»�ӣ��Ľ���5�·ݵ��F�ڣ������҂�����Ҫȥ�M��һ��ɳ����ӣ��҂�Ҏģÿ��Ҳ����5080�ˣ�����������˶����_�l����USER��������һЩ�YԴ���������҂��Ї��^���Ñ�CloudStack����һЩؕ�I�������҂��@߅��һЩcommitter�����棬ؓ؟�ęn������committer����һЩ���g�����g���Ї��^���Ñ�������
�����Ў�퓺ܿ�o����^һ�£�����INDEX���@���҂�CloudStack�Wվ�L������r���҂��ùȸ躆������һ�£���Ȼ�҂����Լ�����������Ȼ����lһЩ�\�ӵ���Ϣ���������¬F�ڛ]�ж��٣��������ʮƪ���F��Ҳ������һЩ����ķ������҂����Ժ��ο�һ�£�Ŀǰ�����ڱ�������̎�����L�˔����^���У��҂�ǰ���ᵽ���҂�����ɳ���\�ӣ�Ŀǰ��Ҫ�����ڱ�������
�@���҂��Ŀ��솖���ռ��ρ�����r������CloudStack���fĿǰ߀�nj��ڱ��^�µ��A�Σ����������Ҷ���ȥ�˽⣬�Ј����b�ò����_�l��ϵ�y�\�S����ռ�ı�����࣬��Ҷ����˽⡣
�@�Ǵ���õ�̓�M��ƽ�_�����߽�̓�M��ܛ����һЩ��B��ǰ�������Ͼ���VMware��Server����KM���F�ڲ��ϱ��^��ɢ��������Ҫ���õij��������҂���������˼����@����^�����F�p�A���҂��F�ڽ���߀�Ǖ���CloudStack��ɵ�һЩ��������Փ�Ǽ��g���棬߀�ǰ��ţ��һЩVIDEO���Ǻܚg�͵ģ��҂��F��������һ����ʾ�Ĺ�������ҿ�����ȥ��һ��,̓�M��������Ȼ��Ҫһ�����YԴ�͕r�g���F��CloudStackҲ��Ҫ�����VENDOR�����M����
�ᆖ�����fCloudStack�m����С�͵IJ��𣬶�Openstack�m�ϱ��^���͵IJ���Y�����㌦�@����ʲô�u���
���e�e�����ε����ӣ�Openstack�Ҹ��������^���Q������Ŀǰ���IJ�������ԓ��…�Д�ǧ�_��Ҏģ�����F��CloudStackĿǰ���������f�_���@���������dž��}��CloudStack�Ǻ��m���������ƣ�Ҳ���m��˽���ƣ��ں��ȿ���˽���ƕ�ռ�^�������CloudStack�Լ��������F�ڳ���ȸ����ĔUչ������֧�֬F���҂���������ƽ�_��
�ᆖCloudStack����JAVA���_�l�Ć
���e������Ҫ����JAVA��
�l����M������M��
���e�������ȫ�ð�����CloudStack�汾�����ÿ��]�κθ��M����鰢����LI…�Q�h�ˣ��㲻��Ҫ���κ��öȿ��������������������}ȥ����ֻ����ͨ�^��^������������������������ڰ�����CloudStack���кܶ��̘I��˾���Լ��İ汾����Ҫ������m��֧�־�Ҫ��Ԕ���Ļ���CloudStack�_�l���̘I�汾ȥ����
�ᆖ����Web…֧�ֵ����÷��棬���ֻ�������ļ��������Ԍ��F�
���e������]�Ў����ǂ���ʾ�����Ҫ֧��VM��Ⱥ�ģ����횽�һ���������룬��������…���@���������ĵ����֣��Լ�����Ñ����ܴa�M�������������@Щ��Ϣ�ṩ��CloudStack��������CloudStack����ƽ�_�����w�F�������ܱ����ġ�
�ᆖCloudStack�����H����֧�ֵ�Ӳ����߀�Є����v�Ĕ����죬DATA…��ʲô�Ƽs��
���e�@߅������Ҫ�w�F��hypervison�����뿴���@��Ӳ���Dz���֧�����Ҫ���_…Server������Ӳ�������б�ȥ��һ�£�hypervisonֻ�����Ďׂ�ƽ�_�����yԇ��My SQLҲ�����ã�Ԕ����ô�ã��ǔ����췽������顣
�l�������ñ��fOracle��My SQL���Ԇ
���e�@��؛ɫ�F������]����ô�@�����F���҂�ֻ��֧��My SQL�����������ǂ��y���ǿ��Ԍ��F�ģ�Ҫ֧������Ĕ�����Ҳ�Ǻ��p�ģ�ֻ�ǬF��My SQL��Փ��Ч���Լ������Զ������My SQL���]��Ĭ�J���@�����棬��Ҫ���˪���ȥ���F��
�ҽ����v���@ô�࣬���еĴ��a�����ڰ�����CloudStack���S����r�¡��F��VMware���ǰ�������S�ɣ�������@߅Ҫ�õ�Ԓ�����Լ����Mȥ��
�ᆖ��һ�K�惦�
���e�������惦���߶����惦֧�ֲ�֧��…���������õ�LVM����…��֧�֣����H�����@���惦����֧��֧���@�N�f��������ô�ӡ�
�ᆖ…
���e���ᵽ����������Ďׂ�ϵ�y̓�M�C���ׂ�ϵ�y̓�M�C��Ŀǰ��һЩ�����c���}�ˣ������f����̓�M·�������õ��^���У��l�����o���M���P�C���ƵIJ������F����^������һ�N��̽ӑ���������ܕ����]centerOS��������һ����OS������һ���ǰ��Žo��������Ӳ���h�������H������������ܘ��;W�j�h���ϵĆ��}��
�ᆖ�F�ڱ����ҵ�APServer���ҵĔ�������Ҫ�x�_����һ���ڱ�������һ���ڣ�APServer�ڱ��������������ڣ����@�ӵIJ����
���e����ゃҪ����…�Dz�������e�����£����ص��@�N���ζ�����ZONE��߅�硣
�ᆖ�Ї��F������Щ֧���_Դ�İ汾��߀����Щ�̘I��˾֧���@�N�̘I�棿
���e�_Դ���@���汾����Ƕ����ã������̘I�汾…�������ǂ���Ҳ�l����5.0�İ汾����Q�˷����ԡ��ڇ�����Ҫ̓�MVDI���@��������
�ᆖCloudStack��ʲôë�������g�y�c���]�н�Q�Ć��}�ܲ����fһ�¡�
���eĿǰ���vCloudStack�ڎׂ���ƽ�_�����DZ��^����ģ���һЩ��^��ȥ���Ѓɰٶ����^�eҪ��Q�����������ģ�KҪ֧�ֵ�Ԓ������}�������S�ļ����ԣ��еĕr��߀���ܝM�⣬�@���_�l���H�^���е�һЩ���}��Ԕ�����f��Ŀǰ���H��ʹ�õ��^���У�CloudStackҲ�ã��������õĕr��ֱ����CloudStack�汾����õ��ļ��g֧�֛]����ô�������������}����ܺ��y��Q�������Ҫ��һЩ�Q�װ汾��֧�֡�
�ᆖ����ģ�K�Л]��ʲôȱ�c�����焂�žW�jģ�K���惦ģ�K��
���e�F�ڱ��^��Ć��}��4.1����ܕ��������F��CloudStack����ģʽ��һ�N�oż�ϵ�ģʽ��ÿһ��֮�g���Ǿo�ɺϣ������ѽ����������_�l�Ǻ����ģ����nj����µ����M���_�l�]����ô���ף�4.0�ѽ��l���ˣ�4.1�ĕr��������^��Ą������������ľoż�ϲ�һ�£����ܸ���ģ�K֮�g�����ӵ�API����ģ�K��ȥ�������ܷ��㣬Ҫ��һ��ģ�K�����ӷ��㡣
�ᆖ�F���Ј��ϵĸ��Nģ�K֮�g�DZ��^�o�ɺϵġ�
���e����ż��߀�DZ��^�ߵġ�
���c�������ã����߀���ֵ��F�������ˡ��ҁ�����Ͱͣ��ҬF�����Ĺ���Ҳ�ǰ�������_Դ�Ŀ����xen Server������һ�������Ӣ�ģ������������ρ��v�������r�X�ρ��v��������S…���M��һЩ�������@�������S…����һЩ��
�����������}����Ҫ������Ӌ�㣬����ƽ�_�������ҽo��ҽ�B�@�K���������ƴ惦�@�Kȥ���������䌍���@�����ܛ]�@ô���ƴ惦��ԓմ߅�����x�Mί�������x������o���@��һ���C���������һ���������ͷ�����
DFS���҂�����һ���_Դ��ɢ��ʽ�ļ�ϵ�y���ǘI���r�����ģ��䌍�@���_Դϵ�y������߀���ǰ�������_Դ��Ŀ���렎�Z���������ɞ�һ����������_Դ��Ŀ����������һ��DFS��ʲô������һ���_Դ�ģ��p������ɢ��ʽ�ļ�ϵ�y���䌍�@���ļ�ϵ�y�������⾫�����ͨ�õ��ļ�ϵ�y����һ�����е��ļ�ϵ�y���������ڹȸ�FS���ļ�ϵ�y���ѽ��ṩ��C��JAVA��PHPAPI���@Щ���С�
�f����ȸ�FS���䌍�հ�FS��FS�Ķ�λ��Ҫ����ᘌ��ֲ�ʽ�P������ģ����@��DFS��λ��Ҫ�Ǟ黥�W���Á����Ƶġ��䌍���Ǵ�ҿ��������һ�l��DFS�Ǟ黥�W��������ӆ������Ҫ�ǽ�Q�������惦�Ć��}������ߙC�ܺߔU���ԡ�UNIXϵ�y����֧�ֵġ�
DFS����ͨ���ļ�ϵ�y������������һ�������ļ�ϵ�y��Key value pairϵ�y���m�ϣ����N��һЩ�������һ��ӡ������һ������ڹȸ��DFSϵ�y�����ṩ��API�ܺ��ξ���upload��download��APPENDER�ļ���߀�о���SLAVE�ļ���һ����ļ��ς�֮���Dz����ĵģ�ֻ�܄h����APP…�ļ��ſ������IJ�����
SLAVE�ļ���Ҫ��ᘌ��@�N����̎������һ�����ļ����ж������ļ��������OӋ���e�����ӣ��ȷ��f���Ñ����^���ς���ԭ�D���Խ����ļ������W������������s�ԈD�������ж����������ڶ��Ǐ�ԭ�����D�Q�^���ģ��s�ԈD�ͽ����ļ������ļ���ID�����н�Ǣ��Ȼ��e�ľͲ���Ǣ�ˡ�
���һ�����ļ����ӌ��ԣ����治̫���h���ˣ���һ�¾ͺ��ˣ��ļ����ӌ��Ա�����Č��ȡ��߶ȣ���ʲô����֮Č��ԣ�DFS��֧�ֵģ������@Щ�ļ��Č����ن��������������䌍�@����̫���e�ã��ʹ���KVϵ�y���棬�������ڴ惦����ͺ��ˣ�������DFS�����ԡ�
DFS�Ǐ�08���_ʼ���ģ����@���Ŀ�����r��߀���Ї��Ż������@���Ŀ�䌍���ܹ�˾�Ŀ�Ć�ʾ�������@���Ŀ�����r�Ż������ԣ��惦�������ô_���r�Ż���һ��ϵ�y���@��ϵ�y�ǻ��ڼ���ʽ�Ĵ惦�O�䣬���rһ�_�O�������G�Ę��ӣ������ܸߣ����������ijɱ�Ҳ�ܸߣ�һ���dzɱ��ߣ�����һ�����U��Ԓ��Ҫ��200T���@��ƽ�_�ijɱ�̫���ˣ��Ż��Լ���һ���ֲ�ʽ�ļ�ϵ�y��DFS�ļܘ��ĵ�һ���汾����֮����͛]��׃�^�����w�ļܘ����ǻ���������OӋ�����ġ�
�҂��ٿ�һ���@�ׂ���İ汾֮�g�����������c��V1�İ汾���䌍������������ҕ����^���y�ģ�һ������һ�����̵ķ���ģʽ��֧�ֵIJ��l㕽������ġ����@�Nģ����ͨ��֧�ֵ�㕽Ӕ���1K���ҡ�
V2��V1���˸�������ȡlibevent�죬�űP�x���@�KҲ�nj��T�ľ��̣�����ģʽ��V1���M����Ч���@��ģ��֧���B�Ӕ������_��10K�����p�ɵġ�
V3�䌍����һ���������܉�Ѻܶ�С�ļ��ϲ��惦��һ�����ļ�����ȥ���䌍��Ҫ���ǽ�Q����С�ļ��Ĵ惦���}������e�`С�ļ��惦��������Ԓ���z�����dz����ġ�
V410�·ݰl����V4������������̫�࣬�����Ǻܺ��ε�һ�l��֧���Զ��x��storage Server ID��������Server ID��ַ����֮���ܕ������㼯Ⱥ��r����һЩ�{��֮ģ���Ȼ��ǰҲ����һЩ������֧�����ID����֮���܉��Ԅ��{���������@�����ܲ����e�������む��Ⱥ����ͬ�r��ID�ĕr���ܕ�ӿ�FһЩ��y����r��
ӛ���҂���һ��DFS�ļܘ�������DFSֻ�Ѓɂ���ɫ����ҿ��Կ�һ�£���߅�Ǵ惦���������������Ǻ��ķ���������Q��������Ⱥ�����ģ�������Ⱥ���X��ļ��惦�Ǵ惦����߅�@�K�ģ������г���һ��һ�еģ�һ����һ���M���ļ���һ���M����������ģ�������RADI1���������R����P��Ȼ��ÿ���M���ļ������دB�ģ��ļ��ς��ρ�ֻ�ܷ���һ���M���棬����@���M�������������������@���ļ��͕����������ݡ��@���D���������@�ӡ�
DFS��Ⱥ��������з���������ƽ���Pϵ���惦�������ǷֽM�ķ�ʽ����ͬ�M�Ĵ惦������֮�g��������ȫ�����ģ��������κ�ϵ���������κε�ͨӍ���ٿ�һ���@���D�������v���@���������@���D��Ⱥ�Ęм~������ô֪���@Щ��Ⱥ�Ġ�r�������@���惦��������Ҫ�����R��ġ�
�����҂���һ��DFS�ς��ļ������d�ļ���ʲô�ӵ����̣��䌍�������@�����̿��܌�DFS�����C�ƿ��ܾ�������һ��롣
�҂���һ���ς��ļ������̣�����client����tracker����Ҫ�ς�һ���ļ����@���ļ���ԓ�ς�����ȥ�����d�@���ļ���clientȥ��tracker���������dָ���ļ���storage���������ļ�ID��
�����҂���һ��DFS�����c����ҿ��Կ�����DFS�Dz���Ҫ���y��name Server�ģ����@��ƿ�i�o�����ˣ�������]���@����ɫ���������Ĵ惦�r�����÷ֽM�ķ�ʽ���@����ʽ���^���Σ�Ҳ���^�C�ӡ������fҪ���d�ļ�����ͨ�^��M�ķ�ʽ���惦���������nj��ȽY���ģ������چ��c�Ć��}���҂����d�ļ��ĕr���Ժ�Ŀǰ������Web Server�������ã��҂����������ṩ����չģ�K��Ҳ�����ڴ惦����������ֱ�Ӳ���������߲���UNIX���ٰєUչģ�K�b��ȥ������ֱ��֧�����d�ˡ����⌦��С���ļ�����֧�ֵúܺã����ļ�Ҳ�ǿ���֧�ֵģ��������ļ��]�����e֧�֣�����DFS�dz��ں��εĿ��]���������ļ���Ŀǰ�]�����։K�@�N��������V3�_ʼ�����Ԍ�����С�ļ��ܺõ�֧�֣�֧�ֶ��K�űP���䌍�dz��h������ʹ���ϵ�y�_�����õ�Ч�ʣ��䌍�����e��Ĵ惦������ֱ�Ӓ�αP����Ҫ��RADI�ˣ��@���ļ�ϵ�y���C�㔵���Ŀɿ��ԣ��䌍���Ǜ]�б�Ҫ��Ӳ��RADI�ģ��DZ��^�]���ġ����һ�����c����֧����ͬ�ļ�����ֻ����һ�ݣ��������g��
�����v��DFS��name Server�����Ҫ�惦�ļ����������y���DZ���Ҫ��name Server����ʲôDFS���Ҫ�@���������������������v���M�����ѽ��f���ˣ�DFS������ļ�ID�����ɴ惦���������������ҷ����oclient�ģ�clientֱ�Ӵ��ڱ��˵��wϵ����ͺ��ˡ��ļ�ID�����˽M����߀�������ļ������܉�ֱ������ԓ�ļ�����λ���@���wϵ������ļ���
����һ���ļ�ID��ʾ������ǰ���ǽM�����ɹ���T�Լ����x�ģ�����ڶ������ǴűP�����DFS֧�ֶ�űP���ڶ����־��ǴűP�ı�ʾ������M���控һ���űP����̖��M00�ͱ�ʾ��һ�K�űP��M01�ͱ�ʾ�ڶ��K�űP��00��0C�͌����ļ�ϵ�y����Ĵ惦Ŀ䛣�DFS���ļ���ֱ�Ӵ����ļ�ϵ�y����ģ�Ȼ�������ļ�ϵ�y�����ǽ���һ���ɼ�Ŀ䛁��惦�ģ�������250M���䌍�@��Ŀ䛔�����ˡ����һ���־����ļ�������ҿ��Կ��������^�L���ļ��������䌍߀������һЩ��Ϣ�����@�ﲻ���w�v�ˡ�
���vһ�£�V3���С�ļ��Ǻϲ��惦�ģ�����ô��λ���@��С�ļ�����ҿ��Կ�һ�£��҂��ڱ�����ID�������������������ֶΣ�����16���ֹ���ÿ���ֶζ���4�ֹ��ģ�������һ�������@���ļ��Ǵ����Ă������ļ���ģ�Ȼ���҂��Ĵ����ļ���IE̖�����ļ����ģ������@��С�ļ���ID����͕�ӛ�d�Ҵ���@��trunk file��ID�������ļ�ƫ������ֱ�Ӷ�λ��С�ļ���ʼ�ĵ�λ��߀����ռ�ö����g��
DFSͬ���C��Ҳ�vһ�£�DFS��ͬ�������I�b���ͬ���䌍����Ƶ�̎�������Dz�ȡbinlog�����������Ǹ��²������ς�������Ȼ��ͬ���ĕr��ֱ�Ӹ���binlog��������һ�cҪע��ģ�binlog����ֻӛ�d�@���ļ����Ͳ�������ͣ��������Hӛ�d�ļ����ݣ���錍�H�ļ������ѽ��惦��ϵ�y����ȥ�ˡ�ͬ���ĕr�����������ķ�ʽ����ͬ���ĵ�λ���ҕ�ӛ�d��һ�����R�ļ������Ҳ�f�����ҵ�һ���M���棬�惦��������ƽ�ȵģ�Ȼ���ļ��ς����h�������d�@Щ�����������@���M�����κ�һ�_��������ȥ����߀��һ�c�����@���ļ�ͬ���������ς���һ�_�惦����������ȥ��Ȼ�������@�_���������@���ļ�ͬ�����@���M����������������ȥ���������ς���ȥ���ς�ֹͣ������IF�ķ�ʽͬ����ǰ��
�ļ�ͬ��ֻ�ڱ��M���M�У�����������storageServer֮�g�M�У�Ȼ����push�ķ�ʽ����Դ�^������ͬ���oĿ�ķ�������
����͕�����һ�����}������ҵ��ļ����ς���֮���Ҳ�ȥ��ͬ���ģ���һ�����}�����ҵ�ͬ�����t�Ć��}��ô��Q�����������^�����_�l��Ԓ�͕�����һ�����}������ͬ�����t�Ć��}�����������һЩӛ䛣��������һЩӛ�֮�������̾�ȥ�L���@��ӛ䛣����������ȥ�L����storage��Ԓ�����ܔ���߀�]��ͬ���^����������ӛ�ȡ������Ҳ���܌����յ��K�������҂���ǰ��Qͬ�����t�Ć��}���҂�������һ���������ܺ��ε����������������֮���Ҽ�һ��sdf��
�惦�����ɵ��ļ������棬�䌍�����˺Îׂ����^��Ҫ���ֶΣ���������Ҫ�ăɂ��ֶ�һ������ԴstorageID��ַ�����ߏ�V4�_ʼ����ID��߀������һ���ֶξ����ļ��Ą����r�g�������ļ��������@�@Щ�ֶη��g����������һ�c�惦�����������r��storage Server�v��ͬ������r��������Ŀ�˷�����ͬ�����ļ��ĕr�g����tracker�յ����֮��͕���һ��Ӌ�㣬���ÿ���惦�����������r�ij��ģ�Ȼ�����յ��@������֮��͕�Ӌ�㣬�@���M����ÿһ�_�惦��������ͬ���r�g������Сֵ���������@����Сֵ�������oӛ�����
tracker Server��ô֪�����@������������һ���ܫ@���@���ļ������Ă��l������һ���l���҂����O��һ��ͬ�������t�yֵ����ǰ�r�g���ļ������r�g�����������ͬ�����Fһ���ļ�����Ҫ�����r�g��Ԓ�����F�@���ļ��϶�ͨ����ȥ���@���ļ��϶������t�ġ�
�ڶ����l������ļ������r�g�����ȱ�ͬ���ĕr�g��С��Ԓ���DZ��F�@���ļ��ѽ�ͬ������ǰ�惦��������ȥ�ˡ�
������ǰ�ᣬ���ļ���ͬ����Ҫ���r�g�Ƕ��٣�����5����Ҿ͕���һ���@���r�g�����Dz����ѽ�����ͬ�������r�g����������@���r�gͬ������ȥ�ˡ�
���Ă��l���ļ��ς���Դ�^storage��ֻҪ֪��һ�l�Ϳ������d���@�����}�ġ�
���d�ļ��ĕr����ͨ�^���^�ɂ��r�g������֪�����@���ļ��Dz��ǿ������d��
����҂���һ��DFSʹ�õĬF�Ŀǰ�ѽ�֪�����õĹ�˾�ж�ʮ��ң��õ�����һ�������Wվ�Ĺ�˾�������惦group�������İق������Ĵ惦�ęC�����ѽ����^800�_�ˣ��惦�����_��6PB���惦�ļ������^1�|�����ľWվ�I�����Ӻܿ죬��Ŀ����Ҳ�ܿ졣��2010���PPT���挑�ĕr��group��������߀�ǬF�ڵ�һ�룬ǰ���솖�������F���ѽ��ַ�һ���ˣ�Ҳ��һ���ĕr�g��
�҂��ٿ�һ��DFS��ʹ�ð�����֧�������w�š����|��58ͬ�ǡ��s���W֮ģ��䌍��Ҫ߀�ǻ��W�Ĺ�˾��������֧���ИI�ģ���������̄��ИI�ģ�Ҳ�����ь��@���ИI�ġ��ҵĽ�B�͵��@��������һЩ�Wַ����Ҹ��dȤ��Ԓ����ȥ��һ�£�����DFS��Փ����������һЩ�ᆖ�Ľ���@���ҵ�������Ҹ��d�µ�Ԓ�����Pעһ�£�����߀��QQȺ��Ҳ���C����܉��c���@���Ŀ�����������������߀��ؕ�I���a�������ܽ����M�����Ǻ��_�ĵ�һ�����顣�x�x��ң�
�ᆖ…
���c�䌍DFS����һ���ֲ�ʽ�ķdz������һ��ϵ�y��Ȼ���������c���䌍ǰ���v���ˣ���һ�c������ֻ�Ѓɂ���ɫ���]�Ђ��y��name Server������Ҫ�Ю��ļ��������@�Ǻܴ�����c�����c��
ĿǰDFS���������^���Σ����ļ���һ�����@�K����������һ���ԣ����Ǐ�һ���ԣ����Ҫ����һ���Ե�Ԓ����Ҫ�����Ĵ��r���ܸߡ�������Ҫ����һ���ԣ���һ����������Ҫ����һ���ļ���a�����ݣ������ǰ��@���ļ����ݶ�����ȥ���@�ӑ����悀푑��r�g�����L�����ґ��ö˕����y�����fһ��ֻ�Ѓ��_�C�������ã����@���r������ô̎�������韩�ġ������һ���Ե�Ԓ�ͺ�һЩ��ֻ����һ�_�C���ǻ����ģ��Ϳ����ς���ȥ���Ȅe�ęC���֏�֮����ͬ���o���ͺ��ˡ�
������ֻ�Ѓ��_�C�����ς��ˎׂ��ļ�����һ�_��������ȥ�ˣ�߀�]�Ё��ü�ͬ�����ڶ��_�������ĕr���@�_�C�����ˣ�ĿǰDFS�ܘ������c���o�λ֏͵�Ԓ���@�ׂ��ļ����ܾ͆�ʧ�ˣ���һ���ԵĴ��r����ܶࡣ
�ᆖ…
���c�@��tracker Server�у��_�C����IP��ַ�Ͷ˿�����ȥ�ͺ��ˡ�
�ᆖ…
���c������Ҫ�DŽӑB���ټәC����Ŀǰ������������Ҫ�ӑB��tracker Server����Ĵ惦������Ҫ�؆����Ժ��ھ�����֮������Ԅ���Ч֮ľ����ˡ�tracker Server��Ҫ�Üp��Ԓ���@�N��r���١�
�������x�x���c���҂�ϣ���@���Ŀ�ɞ鰢������Ŀ�����r�g�Pϵ������߀�л�ӣ������҂���Ո���һλ����ˡ�
�O������Գֵ��F�ڵĸ�λ��ʾ���x���ҕ��v�÷dz��죬��������ʲô���}���ԽY���Ժ����ġ�
�������ҽ�Bһ��������^����Ŀ����inpala���������Ǵ������_Դ��in�F��߀���ǰ�������Ŀ��Ȼ�����õİ���������S��
��һ�����}����ʲô�������^�m�Ϗ��s���\�㣬���������Լ����ӵ��^�̮��У������кܶ����}��Ҳ���dž��}�����^�������m�����@�ӵĈ�����ʹ�ã����Ҳ�����T�ˣ�Ҳ�]���J���@����ʲô���ã��������һЩ��������푑��r�g��ᘌ�������������һ�c��߀��һ�����}�������Ľӿڣ�Hive�ṩ�˽ӿڣ������M�к��������IJ�ԃ��
�����@��inpala��ȫ�ڹ����ϸ�Hive�dz������ġ��v���ٶȵ�Ԓ��߀��һ����ʲô������HBase�����ܿ죬ֻ����Ĕ����Mȥ�@�����E�������L�r�g�����@߅���ģ����п�����ETL�����п��ܛ]��ETL���oՓ��ô��Ҫ���������������L�ĕr�⡣
�҂���һ���ڴ�̎���������ȵ��ˣ����ȿ��ȸ裬�ȸ��ڌ��r̎����������������һЩؕ�I�������ǃɂ��Ǽ��g�ϵ����c�����õ��д惦���ȸ����ñ��^�������ǣ����ڿɬF�Ĕ������������д惦�������@�ӵĔ�����ʽ���д惦�䌍����һЩ���ܵģ�������Փ�������v�ñ��^�������@�������ļ��g���������_���ĺ�������Ҳ���ܐ�Ľ��
����߀��һ�ҽЁ��R�d��ǰ������˹�S��˹�������ĕ��h��Ҳ������������Redshift�����]�й�ȻһЩ�������҂��ԵþͿ����ˣ��]��ʲô���ԌW���ġ������������C���M�ģ��㸶�M�ͺ��F��������ֻ���õ���ęC���������ö��e�˵ęC�����@�����ȸ�ķ������һ�ӣ������҂��˲�̫���Á��R�d�@��؛ɫ��
�҂���һ�������@ЩՓ�Ļ���һЩ�����ߵ��������_Դ������ʲô�|������һ�����ǰ�����Drill���F���кܶ���Ը���_��ӑՓ�@���|�������]���κεı��|���Mչ���F���҂���B����ɂ���һ����Drill��������ʮ�·ݱ��^�������ģ����ǵ�ʮһ�·ݝu�u�����ˣ���߀��һ������Shark��Spark����Ҳ���@�����������ǡ����һ�������҂�����Ҫ��B��inpala��
�҂����^���������@�ӵĖ|������������̎�������B�h���������Ķ�λ������ʲô����һ���䌍ֻ��һ���������µ���inpala���^��ҕ�x�շ������ٶȣ�푑�������ֻ����һЩ���ε����飬�ض���һЩ��ԃ�������y�ķֲ�ʽ��MPP�Ĕ�����ȔM����Ҳ��Щ�L̎�������������c��������MPP��˼·��һЩ�ӿڣ������Ҳ�����MPP���F�惦Ӳ�������߾W�j�O�䣬�ҾͰ����Q����朼ҵ�HDMS���������dz������r��߀�о����������ṩ���ԵĔUչ���@������������̎���ĭh�����еĶ�λ��������M�к��β�ԃ��Ԓ�����Ժܴ�ˮƽ�ώ͵��㡣
�҂���һ����������Щʲô�����Ĺ����䌍�ܺ��Σ����Ǹ�Hive��������l�R�ģ�ͬ�r��Ҳ��һ��ˮƽ�ϵĔ���������������Hive���H�ǔ����醖���������������D�Q�����г���֮��Ė|����������������Hive�F�еķ���������������Hive�ĽM�������]����metadata������ֱ�ӵ�Hive�������Щ���x�������͵õ��@Щ��Ϣ��ͬ�r����Ҫ��Hive��DDL�����Ƕ��x�Z�ԣ�ͬ�r����JDBC��ODBC����ȫ��Hive�ģ��Ӷ��������b�����ѽ��M����Hive�����˼��ݡ��@߅��Q����ǰһ��Hive����Ҫһ�����ϣ��ڶ���Ÿɿ����ɹ��ģ�һ������������ˣ��@�����Ѓrֵ��һ�c��
�҂��eһ�����ε�������ҿ�һ���@������ô�õġ�����߀��Ҫ��һ��Hive�����Խ�һ��������߀��Ҫ��Hive�є������Mȥ�������Ժ���Ϳ�����impala�����Կ��������Hive���ı�����������ԃ���@��һ���dz����ε����ӣ��������f�ģ���ô������������
�@һ��҂���һ������inpala�ļܘ�������inpala��һ���]�Ь�˹�ظ���ġ�inpala�ض�Ҫ�������ػ������üt�����ģ�ÿһ��inpala�������OӋ�Ą������t������ÿ����Ҫ���ġ�
�҂���һ������ô���@���ٶ�����ȥ���@�������^ţ�ĵط����@߅��B�ɂ����һ��SQL�䌍���Էֽ�ɞ�ܶ����е�С�Ć�Ԫ�����������^һЩ���y������Ė|����֪���������o��һ�����еĔ����䌍�����ǂ��|����������һ����ȃ��ȵĔ�������������ˈ�����һ�ӣ�ÿһ���Y�c�Д����xȡ������ȵȡ�
�@һ퓰��������ɂ��Y�c���Ԫ���������С���еĆ�Ԫ���e�����ӣ��҂���醖һ���Dz��Ǫ���δ�����������^���ۺ��ô���ȯ����߅����Ʒ��������߅�ǿ͑���������߅��ID�B���������҂�SQL���ճ����x������������Ʒ���֣������˃r���˃r�����Č��H�N�۵ăr�X�����ԣ��������|�����^�F���ڱ��ϏV���҂���һ���ǂ�SQL���Էֽ���@���ӣ����_��߀��Ҫȥ�x�������x�ꔵ���Ժ�����Join���@���ӿ�ֱͦ�^�ģ�������Ҳ�����������҂��ֲ�ʽ�ĭh���£��҂���ô�����ӿ죬��ô����׃�ÿ��Էֲ�����Aggregation�ֲ�����
fragment��Ҫؓ؟�xȡһ������ͬ�r�xȡ�ĕr���ո��@������ɵ�ǰ���M�кY�x���@�������@һ����һ���P�ģ����Ҕ���Ҳ�Ƿֲ��ģ��@һ������ȫ���Էֲ������ģ���һ���҂��є���С�ı���o������ı��������@�����Ĕ������^���҂��͑�ԓ����Ʒ�������ҳ����ĽY�����o�������N�۔����ĽY�c�����^���Ժ�Ͳ���Ҫ����һ�_�Y�c��Join���@��fragment��ʲô�����˃ɂ�Join��������������������ɂ�fragment��Ԓ�����\�еĕr�oՓ�Ǿ���Ҳ�ã�߀��ʲôҲ�ã�һ��߀�б��C�Ĕ�����ݔ���@����������{�䷽ʽ���@���DZM����ȥ���еĻ���ԭ����
�@߅���^�^�۵ĵط����@�ɂ��ĽY������Ҫ���f���@�_�Д����ĽY�c�ϣ�������Ҫ����^�ߣ����������˱��^�ֵļt�������N�_�C���N�۔�����M�_�C��������Ʒ�������@��һ��M×N���Pϵ��
����֮�⣬�����܃��������˺ܶ����飬������Ă�����һ����ȫ��C++���ģ�fragment�ڌ��Hɢ�l���еĕr����ڱ��������g�������@�^HDFS�f����
����������Щ����Ҫ���أ��������]��BDL������Ҫ��ȫ����Hive���ڶ������]��Defined Function�����������]��FT������@��Join�����g����Ժ������h���ܡ�Ȼ������ļ���͵�֧�֣�Avro��RCFile��LZO�ȵȡ�inpala��Trevni�����ܕ������ܶࡣ����@�ɂ�����һ�������ϱȹȸ�Փ�������ǂ�������̫�࣬�_Դ�p�ߎ��ȸ�ǰ��һ�c�c��
���F�ڵ�Join���҂��v�Ĕ��������ȥ��������ϲ��ĕr��ȫ�w�ڃȴ��������ģ��@�����І��}���������ˣ����п��ܕ����������������M���ѽ����ܕ����M�űP�ȵȡ�
�҂�����һЩ�yԇ���҂��yԇ�õ����ٶȽ���ί�T����һЩ����Ҳ�����s���@�ǜyԇ�õęC�����Á���inpala���_�C��������ֻ���ĉKӲ�P���@���҂��yԇ�ijɹ���
�����퓛]���v�ˣ��@�����Ȳ��ļܘ����@߅��ֻ�v���犣�BE��������һЩfragment��
����І��}��Ԓ�������ģ������������@����
�����˷dz��м���λ���챣�ֵ��F�ڣ�Ҳ�dz������һ���������@�������恆��Ѳ�v�Ļ�ӣ������҂��ڌ���������л�ӣ�������d�´�ҿ���ȥ����C�����ǡ��҂��Ļ�ӵ��˽Y�����x�x��λ��
�˺���
|
|
|
|

|
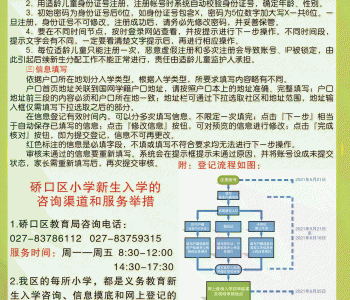
|
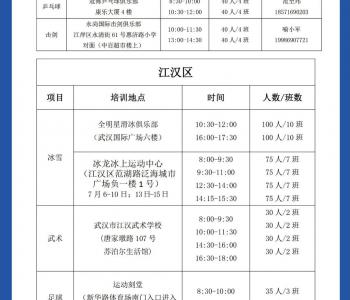
|

|
̓�M�֙C̖�a ����k������� �Ƶ�vi�OӋ ���Ҹ� �Ű����d NBAֱ�� �zĦ�W bitget�ٷ��Wվ
Copyright © 2022 whw.cc Inc. All Rights Reserved. ��h�W �������
��ICP��19009404̖-6 ������ 42010502000112


